
Text Preprocessing PART-01
Published:
Natural Language Processing (NLP) is the study where we try to make machines understand and analyze human language. Processing text plays a pivotal role in shaping the path towards meaningful insights. Effective processing techniques are the key to transforming raw textual data into a format that is amenable to analysis and modeling. In this blog, we will explore various text processing techniques:
Text Cleaning
Before diving into sophisticated techniques lets begin with the basics- text cleaning. Basically it involves converting all the words in a text to a similar form and removing unnecessary words and punctuations from text. Let’s think of an example: CAR, car, Car these words have the same meaning and they can be just written as car. But while working with text data these will be redundant if we think of them as 3 different words. So we need to convert all text data into similar cases. Lowercasing the words is one of the most common practices in the NLP projects.

By using the python built in lower() method we can convert text data into lowercase. In the above text it seems there are some html tags. Most of the texts in the NLP projects are scrapped from different websites. Hence we need to remove html tags from our text as those tags do not add any value to our data. We can use regular expressions to remove html tags from our data.

Moreover, there might be cases when we need to remove punctuation from text. Hence we might need to use regular expressions to remove punctuation from text.

Tokenization
Token is just a fancy word for a symbol. Usually token means a word which has meaning and cannot be broken into smaller units. Tokenization means splitting a sentence into a sequence of words. Let’s give an example,
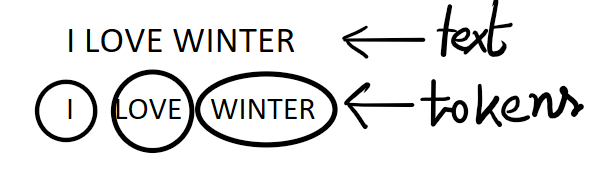
One of the most common techniques for text tokenization is the whitespace tokenization. In this technique we split the sentence based on the space between tokens or words.

However, splitting sentences based on whitespace can be troublesome as there might be multiple spaces between words and handling that will need some change in our code. So far we have been using pythons in built libraries to process texts. However, some of the functions are so much easier to use implementing them with a library like “NLTK”. We can use the “word_tokenize” function from nltk.tokenize to convert our text into tokens.

Like word tokenizer there is a sentence level tokenizer in nltk package which separates sentences from texts.

Text Processing ain’t done yet!! Check Out my next blog for more on Text Processing!! Find the code File Here.