
Text Preprocessing PART-02
Published:
Lets start from where we left off in the first part. In this part we are going to focus on some of the most used text processing techniques. This blog completes the text processing techniques. Lets dive….
Stop words
One popular preprocessing step in text processing is stop word removal, which is eliminating frequently used words that usually don’t add much to the sense of a sentence. Often called “stop words,” these words include everyday phrases like “and,” “the,” “is,” and so on. Eliminating stop words from the text helps the reader concentrate on the most important terms. We can utilize the Natural Language Toolkit (nltk) module to remove stopwords. The below code portion shows the nltk package’s list of stopwords:

A python code example of how to remove stopwords is demonstrated in the following image. The remove_stopword() function takes text as an input and removes stopwords from the text and returns the clean text.
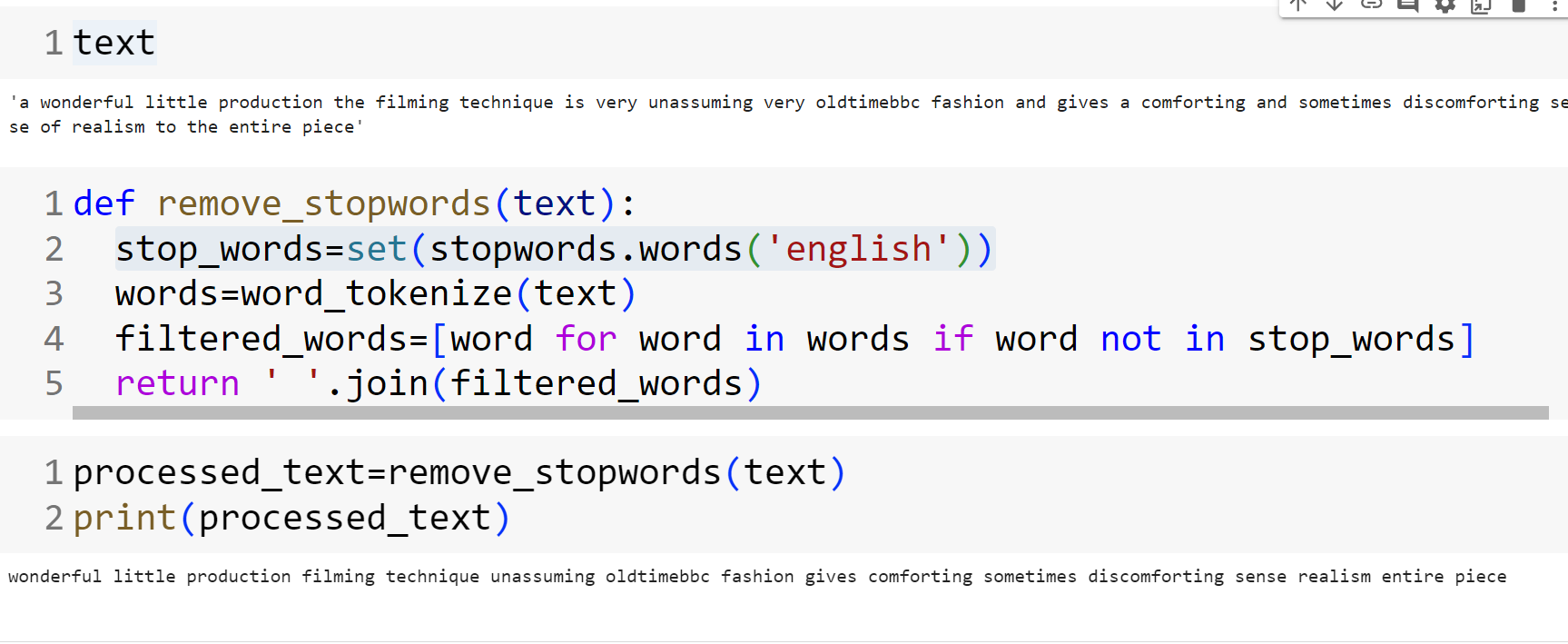
Different libraries may have different sets of stop words, and you might choose to customize the list based on your application or language.
Parts of Speech Tagging (POS Tagging)
A key job in Natural Language Processing (NLP) is part-of-speech tagging (POS tagging), which is giving each word in a phrase a particular grammatical category (part of speech). In the English Language; Nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunctions, and interjections are the basic components of speech. For many NLP applications, including text analysis, information retrieval, and machine translation, POS tagging is essential as it offers valuable insights into the sentence’s syntactic structure.
Hence you might need to do pos tagging based on your taks. Below is an example on how to use the nltk “pos_tag” method to get particular parts-of-speech for each word in a sentence.
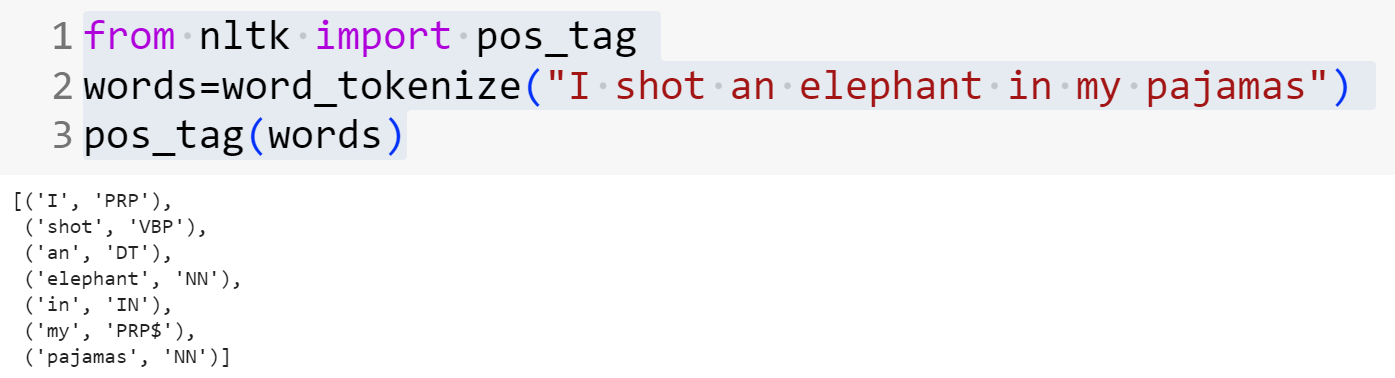
In this output, each word is represented as a tuple where the first element is the word itself, and the second element is its part-of-speech tag.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is an essential job in Natural Language Processing (NLP) that identifies and classifies entities (such as names of people, organizations, locations, dates, etc.) in text. Applications such as information retrieval, question answering, and language interpretation all depend on NER. This is an example of Named Entity Recognition utilizing the Natural Language Toolkit (nltk) package with Python:
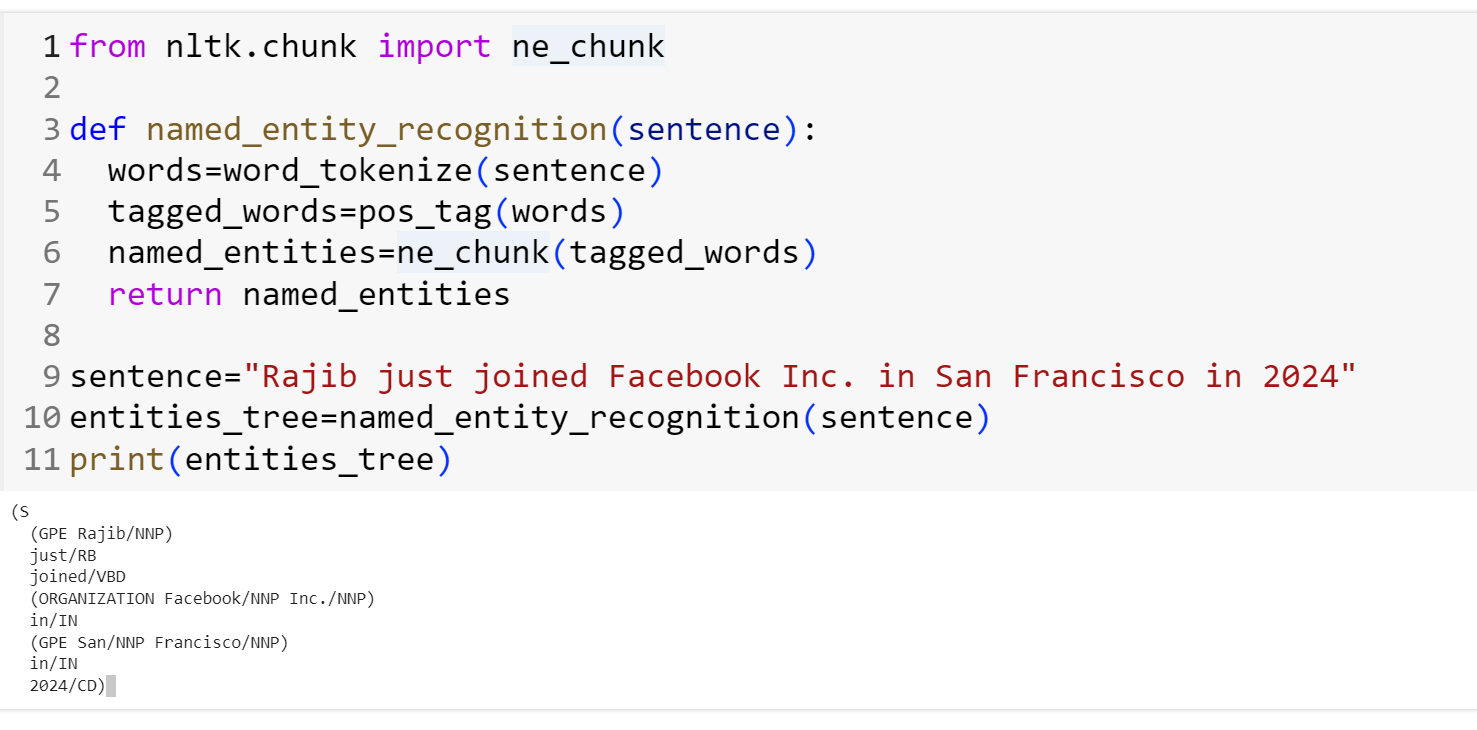
In this output, named entities are marked with their corresponding entity types, such as ‘ORGANIZATION’ for companies and ‘GPE’ for geopolitical entities (locations).
Keep in mind that there are other powerful libraries and models, such as spaCy and the Natural Language Toolkit (nltk) with different underlying models, that you can use for Named Entity Recognition depending on your specific requirements and preferences.
Stemming
In Natural Language Processing (NLP), stemming is a text normalization approach that reduces words to their base or root form, often known as the stem. Words with comparable meanings should be grouped together via stemming, even if their inflected forms differ slightly.
In the process of stemming, terms like “caching” “cached” and “caches” would be reduced to the common stem “cach” This can help with a number of NLP applications, including text mining and information retrieval.
Let’s get the idea of stemming in practice:

It’s important to note that stemming has its limitations, and sometimes the resulting stems may not be actual words. For example, “reduce” is converted to “reduc” which is not even a word.
Lemmatization
In Natural Language Processing (NLP), lemmatization is a text normalization approach that reduces words to their dictionary-based or basic form, or lemma. Lemmatization generates legitimate words and takes the word’s context into account, yet its objective is identical to that of stemming.
Lemmatization is the process of searching up a word in a lexicon and returning its base or dictionary form, as opposed to stemming, which removes prefixes or suffixes to arrive at the word’s root form. This method yields more accurate results by taking into account a word’s grammatical meaning.
Lets see lemmatization into action:

In above there is a parameter passed into the lemmatize method “pos=v” which is used to lemmatize the verbs in the sentence. By default it’s set to noun. Lemmatization is commonly employed in tasks such as information retrieval, question answering, and language modeling.
Now one of the important things is when to use stemming and lemmatization? Stemming might not always stem words into meaningful ones but it’s faster in processing text. On the contrary, lemmatization uses a dictionary for converting words into their original form. Therefore, extra space is needed for lemmatization. So between these two there is always a trade-off scenario and you need to decide on which one to use based on your need.
This brings us to the end of the text processing techniques. In the text processing part I have tried to introduce you with the most common techniques used in natural language processing. Feel free to reach out to me on LinkedIn for any suggestions. Find the code File Here.